Quadrupedal robots have demonstrated impressive locomotion capabilities in complex environments, but equipping them with autonomous versatile manipulation skills in a scalable way remains a significant challenge. In this work, we introduce a cross-embodiment imitation learning system for quadrupedal manipulation, leveraging data collected from both humans and LocoMan, a quadruped equipped with multiple manipulation modes. Specifically, we develop a teleoperation and data collection pipeline, which unifies and modularizes the observation and action spaces of the human and the robot. To effectively leverage the collected data, we propose an efficient modularized architecture that supports co-training and pretraining on structured modality-aligned data across different embodiments. Additionally, we construct the first manipulation dataset for the LocoMan robot, covering various household tasks in both unimanual and bimanual modes, supplemented by a corresponding human dataset. We validate our system on six real-world manipulation tasks, where it achieves an average success rate improvement of 41.9% overall and 79.7% under out-of-distribution (OOD) settings compared to the baseline. Pretraining with human data contributes a 38.6% success rate improvement overall and 82.7% under OOD settings, enabling consistently better performance with only half the amount of robot data.
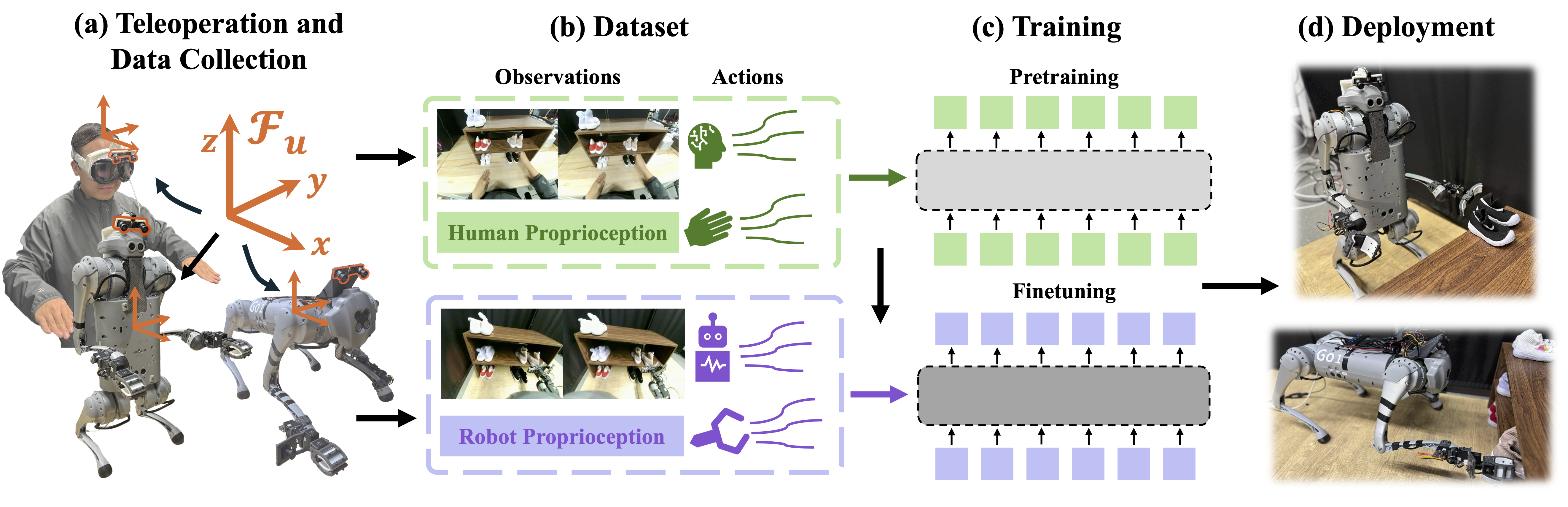
Our system uses an XR headset for data collection, capturing egocentric human data and teleoperated robot data, all mapped to a unified coordinate frame. The dataset consists of aligned vision, proprioception, and actions from the human and the robot. We adopt a two-stage training process: the modularized cross-embodiment model is first pretrained on easy-to-collect human data, and then finetuned on a small amount of robot data. The resulting Human2LocoMan policies can be deployed on real robots for versatile manipulation tasks in both unimanual and bimanual modes.
We develop a unified system for both robot teleoperation and human data collection. Our teleoperation system controls the 6D poses of end-effectors, gripper actions, and the rigid body where the stereo camera is mounted (the torso of LocoMan, the head of human). The coordination of whole-body motions expand the workspace and camera sensing ranges. Our teleoperation system is fast-response, stable, and user frendly, by incorporating interpolations for fast movements, handles and recovery from self-collisions, singularity, ground-collisions, and joint limits.
We mount a stereo camera on the VR set to collect first-person view of human videos and capture human's hand and head motions within a unified coordinate frames as the robot embodiments. Through the simple interface we designed, a human operator without robot access can easily collect dozens of trajectories by themselves within minutes.
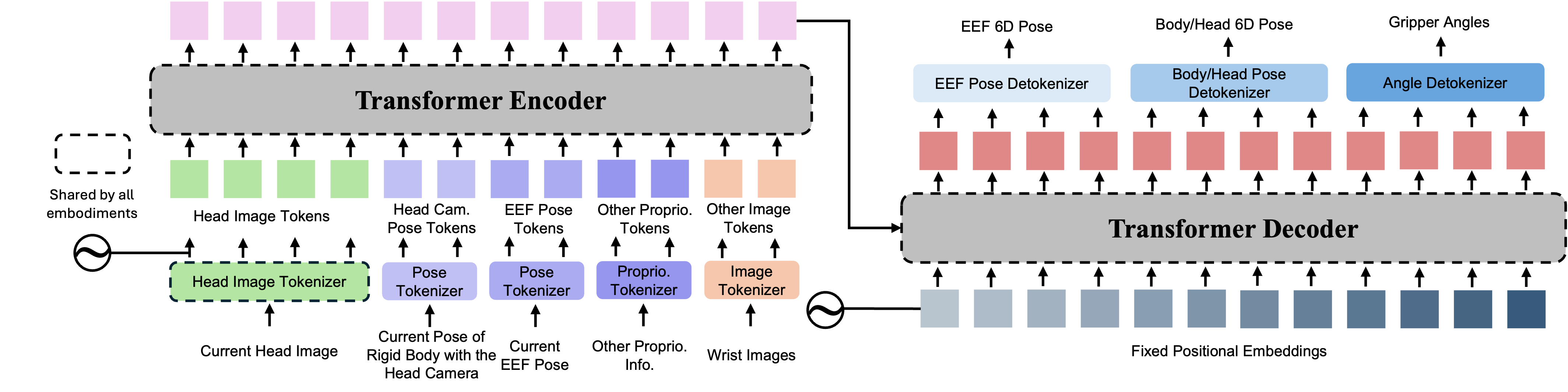
Our learning framework is designed to efficiently utilize data from both human and robot sources, and account for modality-specific distributions unique to each embodiment. We propose a modularized design Modularized Cross-Embodiment Transformer (MXT). MXT consists mainly of three groups of modules: tokenizers, Transformer trunk, and detokenizers. The tokenizers act as encoders and map embodiment-specific observation modalities to tokens in the latent space, and the detokenizers translate the output tokens from the trunk to action modalities in the action space of each embodiment. The tokenizers and detokenizers are specific to one embodiment and are reinitialized for each new embodiment, while the trunk is shared across all embodiments and reused for transferring the policy among embodiments.
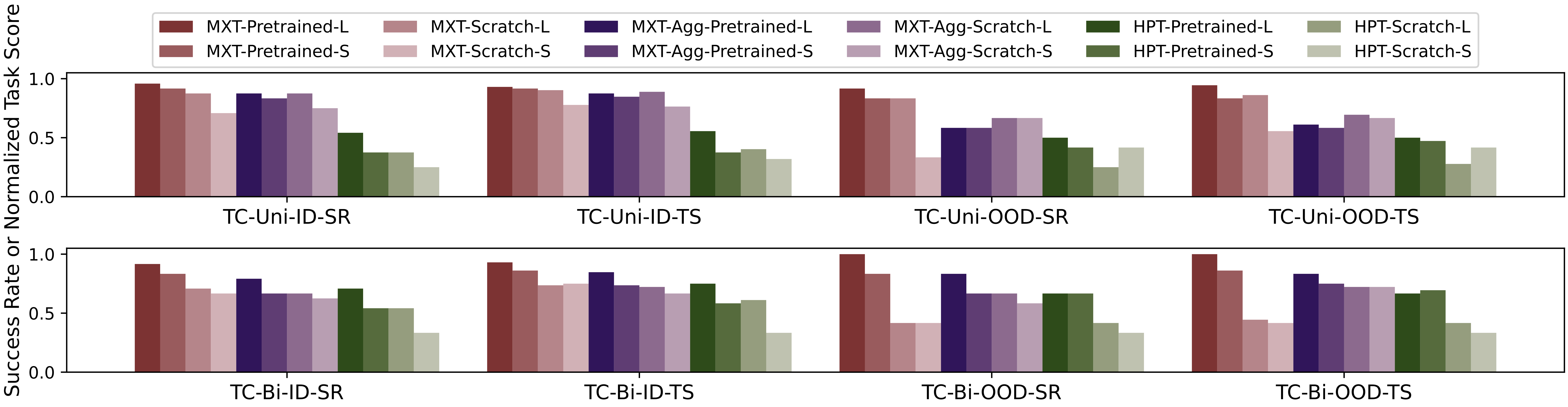
We report success rate (SR) ↑ in % and task score (TS) ↑ for each task. We highlight the best performance in bold and the second best in underline. ID results are based on 24 trials, and OOD results on 12 trials.

We compare MXT, its ablation MXT-Agg, and the baseline HPT on SR and TS.
Here, L
denotes the larger training set (40 trajectories for TC-Uni, 60 trajectories for TC-Bi),
while S
denotes the smaller training set (20 trajectories for TC-Uni, 30 trajectories for TC-Bi).
We thank Jianzhe Gu for the initial camera mount design. We are grateful to Yifeng Zhu, Xuxin Cheng, and Xiaolong Wang for their valuable discussions and constructive feedback. We also thank Alan Wang for his support during our experiments.
@inproceedings{niu2025human2locoman,
title={Human2LocoMan: Learning Versatile Quadrupedal Manipulation with Human Pretraining},
author={Niu, Yaru and Zhang, Yunzhe and Yu, Mingyang and Lin, Changyi and Li, Chenhao and Wang, Yikai and Yang, Yuxiang and Yu, Wenhao and Zhang, Tingnan and Li, Zhenzhen and Francis, Jonathan and Chen, Bingqing and Tan, Jie and Zhao, Ding},
booktitle={Robotics: Science and Systems (RSS)},
year={2025}
}